Share this post
Extract insights from charts, tables, and images with Storytell’s Vision Ingest
May 9, 2025
.png)
Storytell’s ingestion pipeline now supports visual understanding. With Storytell’s Vision Ingest, you can upload documents that include images, charts, flags, and other visual data and Storytell will extract and interpret the content alongside the text.
This feature is part of a broader upgrade to our in-house Extractor service. The goal is to help users work with unstructured content more effectively by turning visuals into structured, query-ready data.
From cluttered visuals to clear answers
Many of the files our users upload—especially PDFs, PowerPoints, and scanned documents—don’t just contain text. They often include tables, maps, charts, or infographics that carry important information. Until now, those visuals were not accurately ingested by our system.

This meant incomplete data extraction and limited usefulness when asking questions. For example, uploading a slide deck with a bar chart and asking, “What trend does this chart show?” wasn’t possible. The system would skip over the chart entirely or return a generic response.
Storytell’s Vision Ingest addresses that limitation.
It lets the model “see” and understand what’s in an image. That includes recognizing visual elements (like a line graph or national flag), interpreting their context, and describing them in markdown or HTML. Once extracted, the visual content becomes part of what you can search, summarize, and question, just like text.
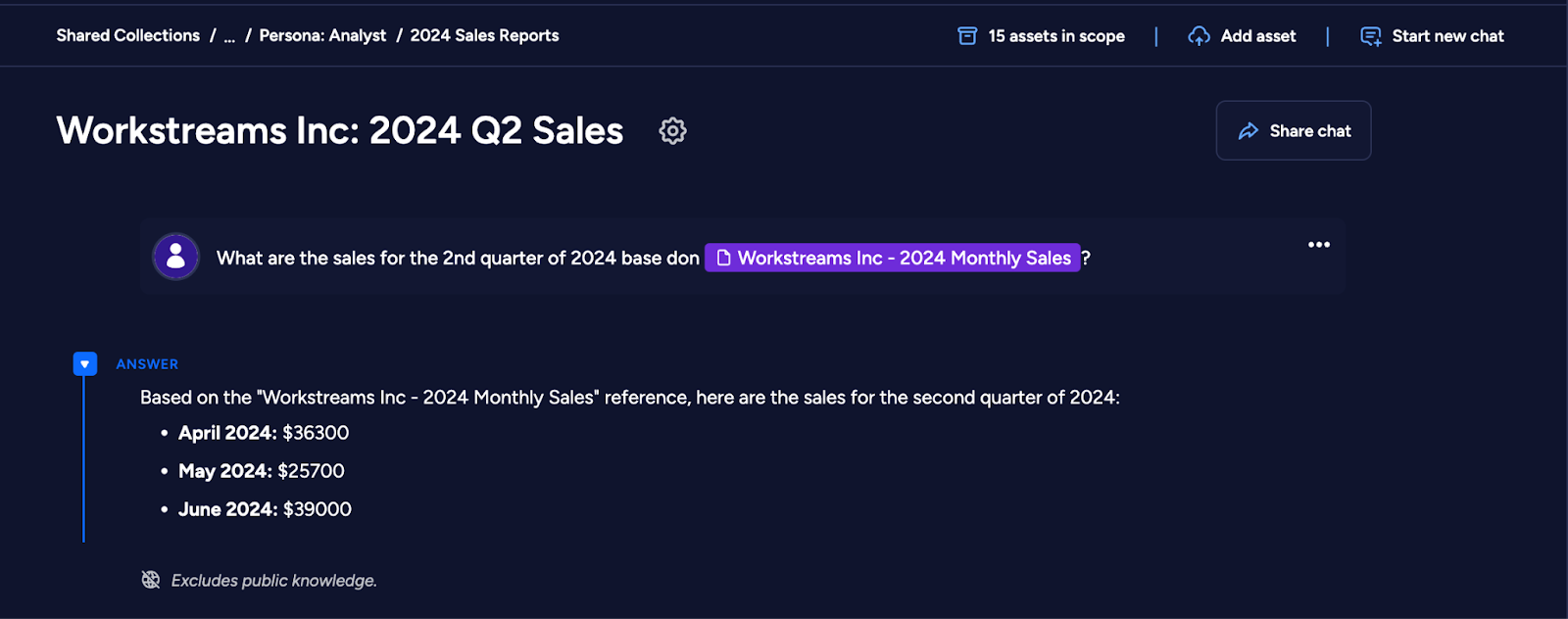
In this example, we asked Storytell about the second quarter sales for 2024, @mentioning the image above which we uploaded in a Collection. The chart is separated into months, not by quarter, yet it was able to correctly provide the data being asked for.
What Vision Ingest sees that others miss
When you upload a supported document (PDF, PNG, JPEG, WEBP, DOCX, PPTX), Storytell automatically routes it through a new extraction pipeline:
- The file is analyzed by a multimodal model that understands both text and visuals.
- Visual elements such as charts, tables, and images are described and interpreted.
- Large files are automatically split into manageable “shards” (defaults to 4 pages per shard).
- Structured content is output in markdown or HTML for better readability and LLM performance.
The result is a cleaner, more complete representation of the file. You can then ask questions like:
- “What’s the trend in this line graph?”
- “Which countries are represented in this infographic?”
- “Summarize the slide with the revenue chart.”
If you turn on Improve Prompt, Storytell will use the visual content to refine your question before sending it to the model, often making it more specific or better aligned with what’s in the file.

Who benefits when your documents become searchable
Vision Ingest is especially useful for:
- Analysts and researchers who need structured data from dense, visual documents.
- Enterprise teams managing large volumes of mixed-format knowledge assets.
- Knowledge workers who often reference charts, infographics, or layered PDFs.
Smarter extraction, cleaner outputs, faster answers
- Visual understanding: Goes beyond OCR to interpret and extract from charts, tables, and images.
- Markdown or HTML output: Clean formatting for better readability and querying.
- Auto-sharding for large files: Documents are processed in sections to maintain context.
- Flexible file support: Upload documents and images without needing to reformat.
- Prompt-friendly design: Pair with “Improve Prompt” to surface better questions about your files.
What’s under the hood?
Storytell Vision Ingest runs on a multi-modal pipeline. It applies:
- Smart sharding to break large files into manageable sections.
- Custom templates to maintain structure.
- A markdown-first output strategy, optimized for both human readers and AI querying.
Known gaps and what’s coming next
- Supported formats: PDF, DOCX, PPTX, PNG, JPEG, WEBP.
- Fixed auto-sharding size: Defaults to 4 pages per section.
- No support for embedded video (yet): Files containing video elements will skip them.
See for yourself and help shape where we go
You can now upload files to Storytell and use Vision Ingest to extract insights instantly. We’re continuing to expand file support, refine accuracy, and improve layout interpretation.
Try Vision Ingest now and tell us how it works for you and your team. Your feedback directly informs the next version.
Gallery
No items found.
Changelogs
Here's what we rolled out this week
No items found.